
Have you ever configured a SmartStore Bucket for Splunk on a Pure Storage Flashblade before?
Me neither, till recently. Part of this exciting role is that you have the opportunity to learn something new every day!
To use FlashBlade to hold the Splunk SmartStore data, you have to first create a S3 bucket within the FlashBlade object store so it can hold all the indexing data.
This was my first time configuring a Splunk SmartStore bucket on a Pure Store Flashblade, so I figured I would document it along the way since this is not something I normally work on, and share it with the community as well while I am at it.
Step by step process:
- Login to the Pure Flashblade console
- Select Storage > Object Store
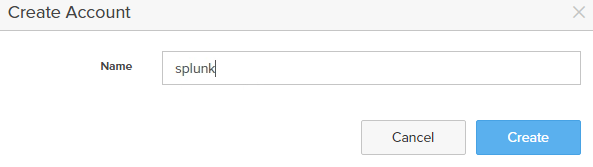
- Create account. Ex: splunk
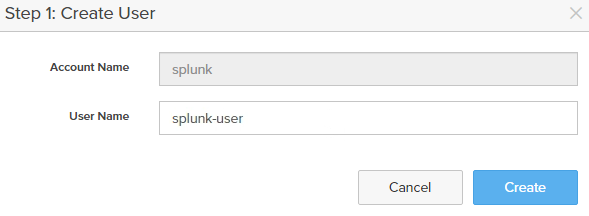
- Create User on the account. Ex: splunk-user
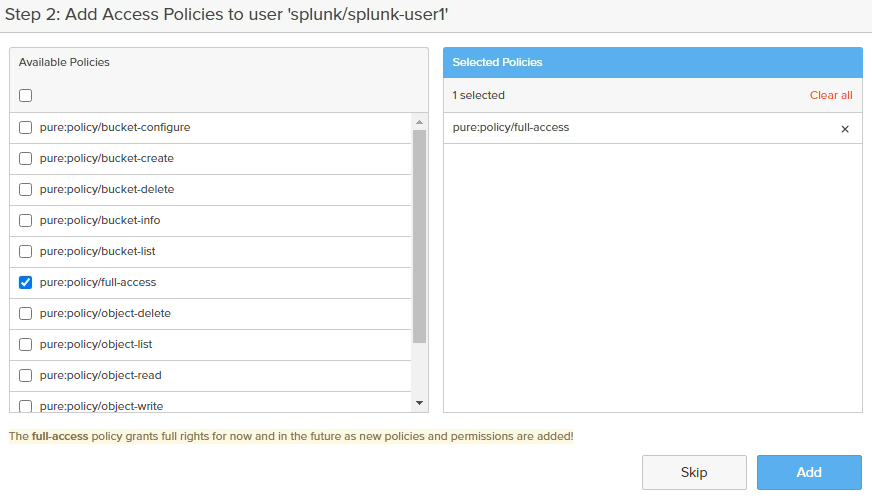
- Provide required access. Ex: pure:policy/full-access
- Create a new key
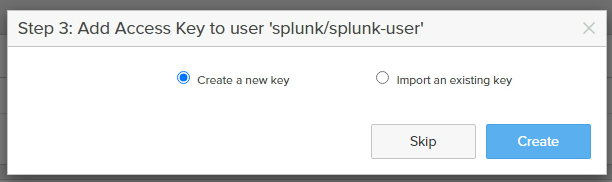
- Make sure to download both JSON and CSV files so you can access them later
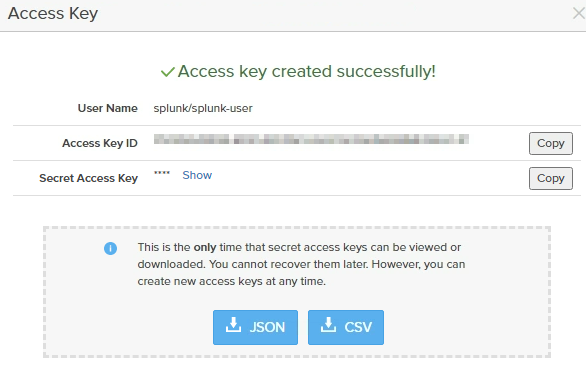
- Create the Splunk Bucket. Ex: splunk-data
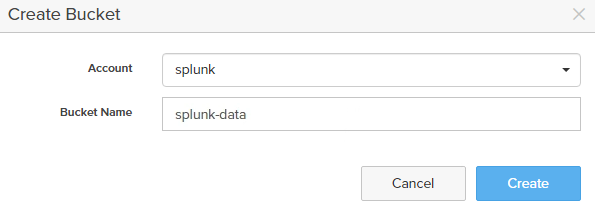
- Go to Settings > Network > Subnets
- Create a dedicated VIP for the Splunk SmartStore just created by selecting “Add Interface”
- Select VIP name and IP address
- Make sure to select data services
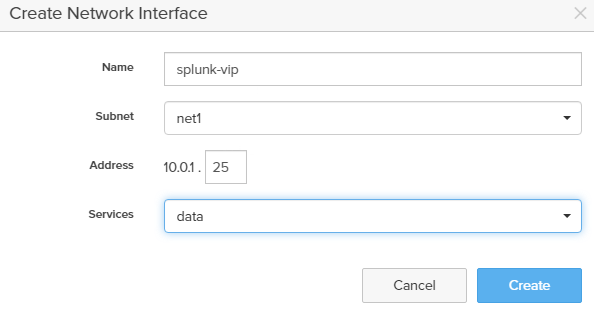
- Below is what the VIP should look like
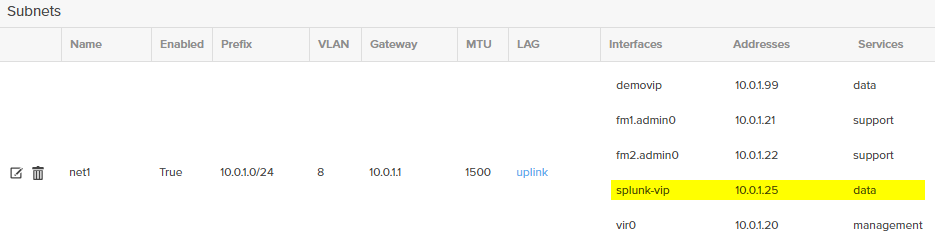
- Done. All tasks on the Flashblade side have now been completed
Example config for Splunk Indexers:
path = s3://splunk-data
remote.s3.access_key = <access key>
remote.s3.secret_key = <secret key>
remote.s3.endpoint = http://10.0.1.25 (flashblade VIP selected)
remote.s3.supports_versioning = false
Was this helpful at all? Please leave a comment 🙂
More information on the Splunk + Flashblade partnership here


