
Don’t you hate it when you are ready to migrate some VMs to your VMware Cloud SDDC, all the data is already pre-synced and the migrations simply fail? I definitely do, and that is exactly what happened the other night.
This error was consistent, and all Replication Assisted vMotions failed. At that point, luckily we still had enough time to migrate those VMs using the Bulk Migration method and sync the data all over again from scratch (these were not database VMs, so they were not huge).
The error was claiming that the appliance was out of space on the /var/log partition, which was relatively easy to identify.
Error example:
vMotion failed. (vmodl.fault.SystemError) { faultCause = null, faultMessage = null, reason = Failed to write header to “/var/log/vmware/journal/xxxxxxxxxxx.x: Error while writing to file. There is no space left on the device }

How do you fix it? Follow the steps below!
- SSH into the HCX Cloud Manager
- Username:
admin - Password:
******** - Enter >
ccli - Enter >
list - Select respective IX node experiencing the issue
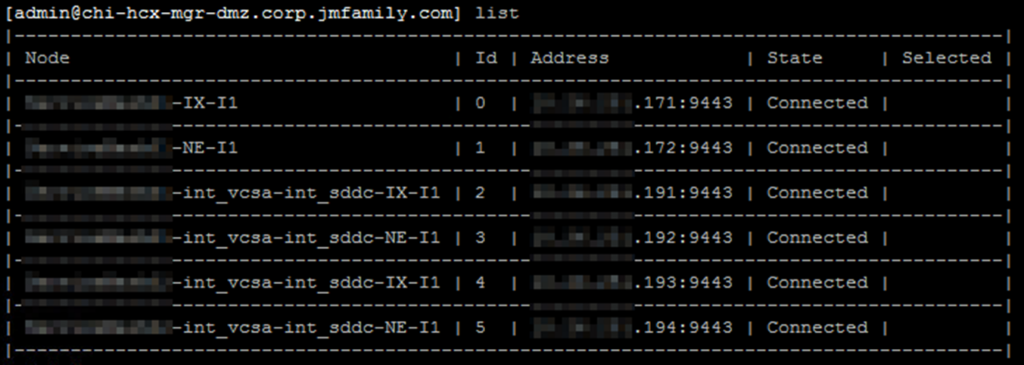
- Enter >
go x - x = the “id” of the IX node receiving the error
- Enter >
ssh - Enter >
df -h
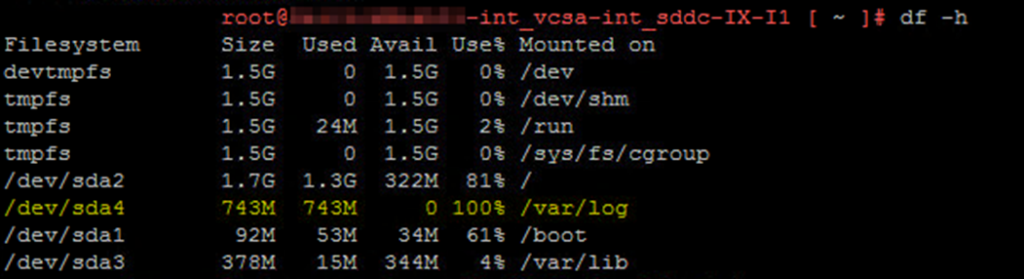
- If the /var/log/ partition shows 100% full, then that is your problem right there
- Enter >
cd /var/log/ - Enter >
truncate -s 0 conntrackd-stats.log - Enter >
rm *.gz - Check your space consumption again
- Enter >
df -h
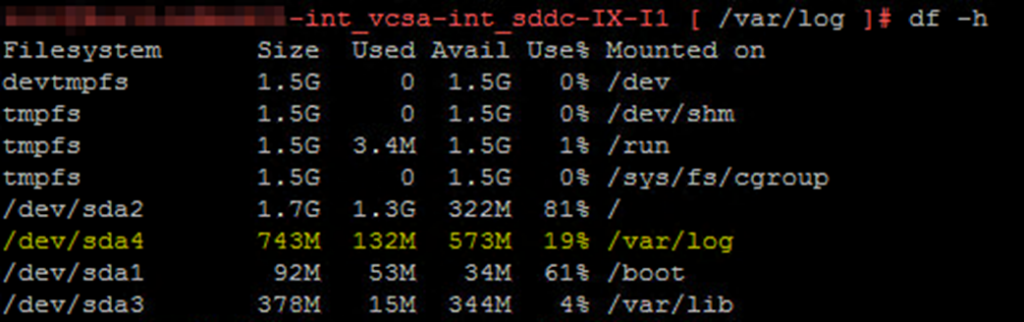
- Now we need to modify the configuration file, so we do not fill up this partition again
- Enter >
vi /etc/logrotate.conf - At the end of the file, modify the value from “/var/log/vmware/conntrackd-stats.log” to “/var/log/conntrackd-stats.log”
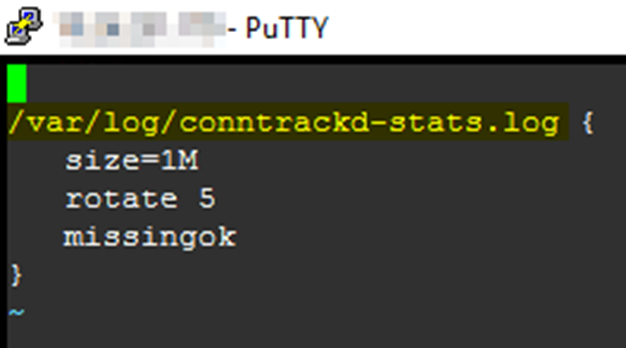
- Save the file
- Reboot the IX node
- PS: You can proceed to reboot the IX VMs from the vCenter console if that is easier
Unfortunately the IX nodes are responsible for migrations, so any pre-synced migrations will have to be re-synced, however, your network extensions will be NOT be affected.


