Pure Storage showed up to this year’s conference as a different company…literally.
New name, same orange branding and a noticeably bigger swing at the “we’re not just storage anymore” pitch.
The theme this time around was clear: Stop managing storage. Start managing data and SLAs.
Below are my favorite announcements from the keynote, in no particular order.

1. Fusion Rebalance and Workload Mobility

Fleet management has always been Pure’s strong suit, but this pushes it further into “let the platform decide” territory.
Fusion Rebalance gives you:
- Automated workload move recommendations across the fleet
- Pre-built move plans with projected latency and capacity impact before you commit
- One-click cutover once you approve the plan
Why it matters:
- No more manually hunting for the array with headroom
- Prevents SLA violations before they happen instead of reacting to them
- Better fleet utilization without a forklift or a spreadsheet
This is Pure treating the array fleet like a single pool of resources instead of 20 individual boxes you babysit separately.
2. Proactive Optimization Recommendations

This one ties directly into the SLA-tier story (Gold/Silver/Bronze) that’s becoming central to how Everpure wants you to think about storage.
The Intelligent Control Plane now actively flags:
- SLA risk before it becomes an incident
- IOPS, bandwidth and capacity headroom per tier
- Which arrays are absorbing too much load relative to their tier
Why it matters:
- Turns storage from a black box into something you can actually govern by policy
- Lets you justify tiering decisions to the business in plain language (Gold vs. Bronze, not “queue depth on array 3”)
- Catches the slow creep toward an SLA breach instead of finding out from a “performance is degraded” ticket
3. Reactive Performance Fire Fighting (the problem they’re solving)

Technically not a product announcement, but the slide deserves its own line because every SA in the room nodded.
This was the “before” picture: arrays full of mismatched, uncategorized workloads with no clear separation by criticality, and admins firefighting performance issues after the fact instead of before.
Why it matters:
- It’s the honest framing of what most environments actually look like today
- Sets up Fusion Rebalance and Proactive Optimization as the actual fix, not just a feature for feature’s sake
- Good reminder for client conversations, half the value here is admitting the status quo doesn’t scale
4. FlashBlade//EXA: Multi-Tenancy, QoS and Bigger AI Job Support
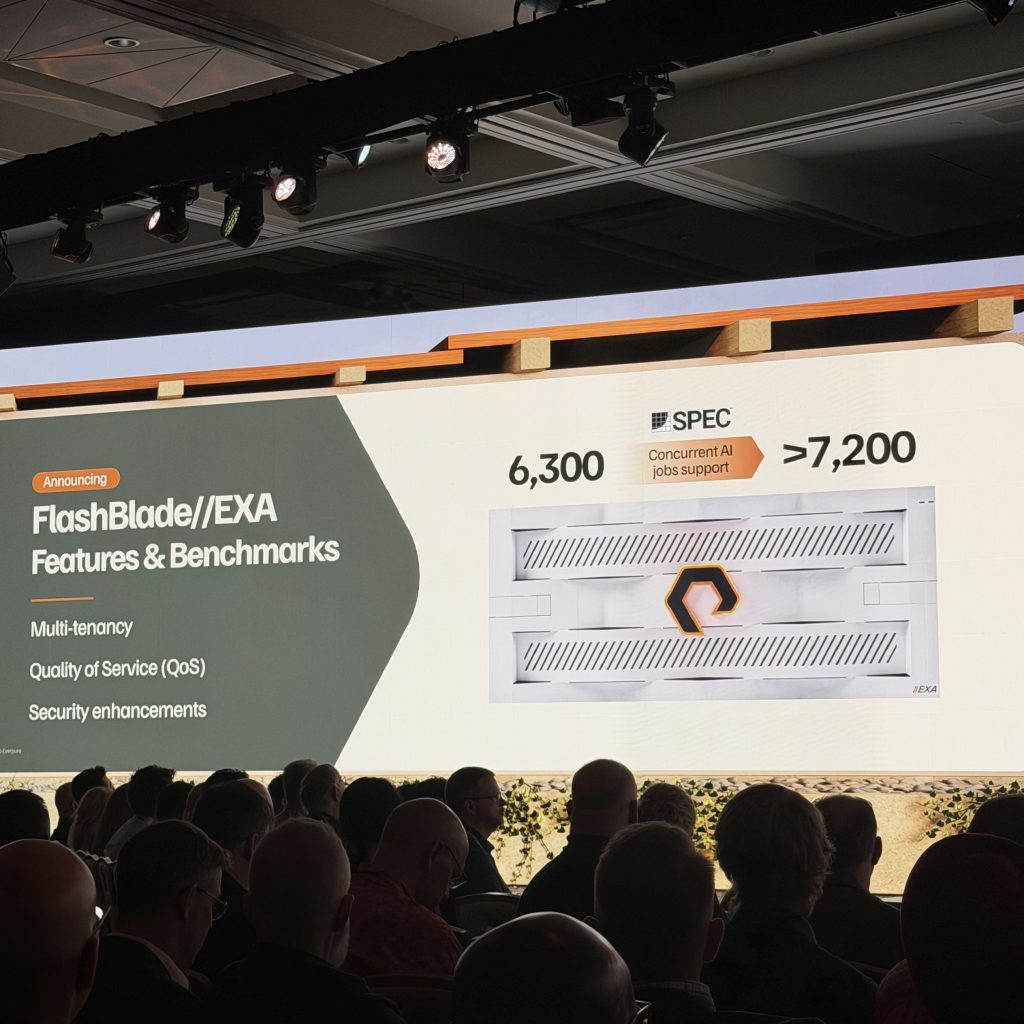
FlashBlade//EXA keeps adding the things large AI/ML shops have been asking for since EXA launched.
New in this round:
- Multi-tenancy support
- Quality of Service (QoS) controls
- Security enhancements
- SPEC concurrent AI job support jumping from 6,300 to over 7,200
Why it matters:
- Multi-tenancy + QoS means you can actually run multiple teams or workloads on the same EXA system without one noisy neighbor starving everyone else
- Support for higher number of concurrent AI jobs is useful when you’re sizing for GPU-dense training clusters
- Security enhancements matter more now that EXA is being positioned as shared infrastructure across tenants, not a single-team island
5. Everpure Cloud for Azure VMs

Native Azure storage that isn’t just “we need you to run some VMs in your subscription.”
Highlights:
- Up to 40% reduction in cloud storage costs
- Mission-critical performance, not just “good enough for cloud”
- Native Azure experience with Azure-native management UI, not a bolted-on console
Why it matters:
- Cloud storage cost creep is real and a 40% number gets Execs attention fast
- Lets you standardize on Purity-class data services for workloads that have to live in Azure, instead of falling back to native Azure disk and losing features you rely on elsewhere in the fleet
- Big deal for hybrid shops trying to keep one operational model across on-prem and cloud
6. Evergreen//One Overdrive
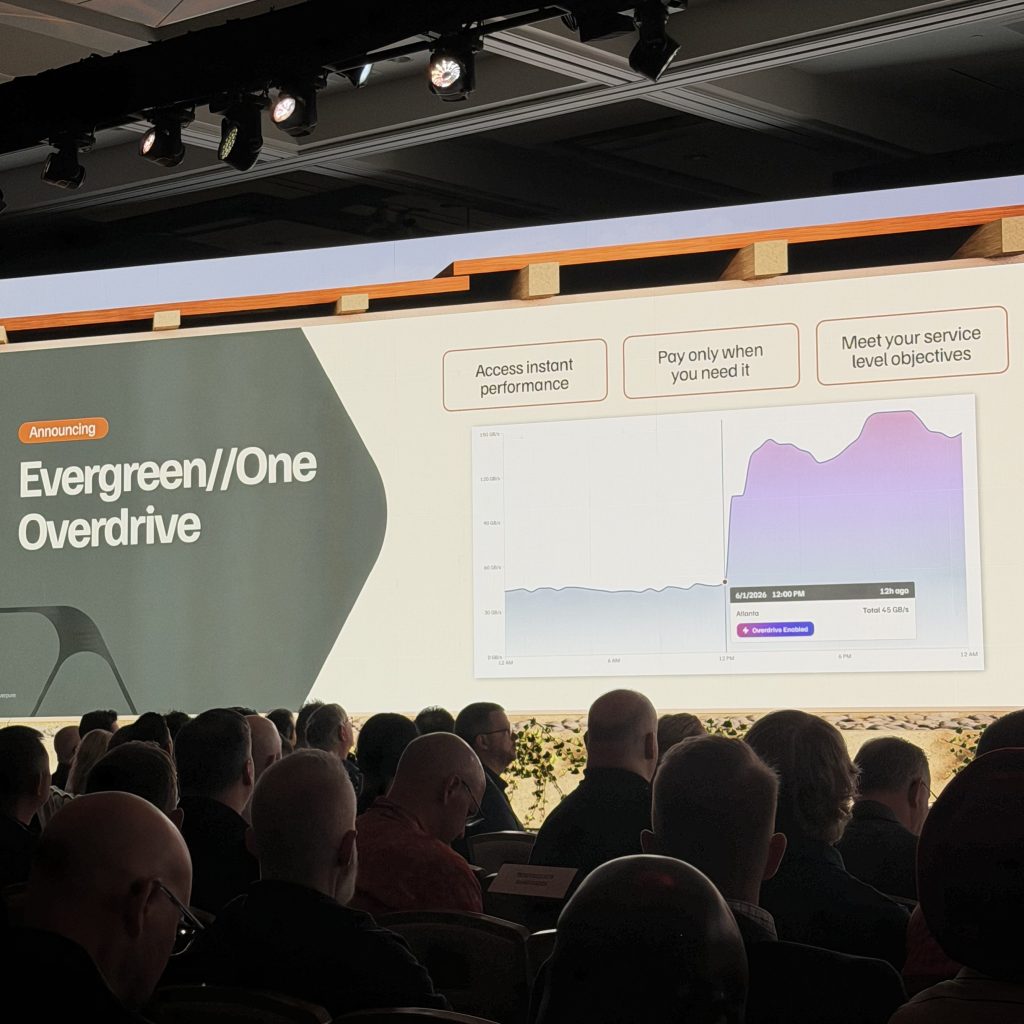
This is Pure leaning further into the “storage as a utility” model.
The pitch:
- Instant access to burst performance when you need it
- Pay only for the overdrive capacity you actually use
- Designed specifically to help you hit SLOs under unexpected load
The demo graph said it all… a flat ~45 GB/s baseline that jumps to 120-150 GB/s the moment Overdrive kicks in, then settles back down.
Why it matters:
- Solves the classic capacity planning headache: do you size for average load or peak load?
- You stop paying for performance you don’t use 90% of the time
- Great fit for predictable-but-spiky workloads (month-end batch jobs, seasonal retail traffic, AI training bursts, etc)
7. Purity Turbo for FlashArray//XL190

The flagship array gets a software-only performance unlock.
What Purity Turbo actually does: the secondary controller, which normally just sits in standby for failover, now actively serves read I/O alongside the primary. Future versions extend that to offloading backup and analytics workloads off the primary controller entirely.
The numbers Everpure is putting next to //XL190:
- 930% more IOPS per rack unit
- 310% more IOPS per watt
- 460% more TB per rack unit
- Sub-100 microsecond, DRAM-class latency
Why it matters:
- Built-in headroom for workload spikes without buying more hardware
- No added management overhead since it’s a software capability on a controller you already own
- This is the array you put Oracle, SAP HANA, and SQL Server on when “we’ll just add another array” isn’t an acceptable answer anymore
My take
The substance here is the shift from “manage storage” to “manage SLAs across a fleet.” Fusion Rebalance, Proactive Optimization and Evergreen//One Overdrive are all variations on the same idea: let the platform handle the part of the job that used to eat an admin’s entire afternoon.
New name. Same orange. Bigger ambitions.